



Content Recommender Systems for Publishers: What Works and What Doesn't


Every digital publisher wants a recommendation engine. Few understand what building one actually involves — and fewer still understand why the Netflix model, which most publishers reference as the benchmark, is almost entirely the wrong reference point.
Netflix recommends from a catalogue of roughly 17,000 titles to a global audience of 270 million subscribers. The content is stable — a film added to the catalogue today is still there next year. User preferences are relatively stable. And Netflix has the data infrastructure, engineering headcount, and time horizon to run recommendation as a core business function.
A regional newspaper recommends from a catalogue that turns over completely every 24 hours, to an audience that often visits once or twice a week, where the most valuable content — breaking news — is the least amenable to personalisation because nobody has read it yet. The problems are structurally different. The solutions need to be too.
This article covers what recommendation architectures actually work for publishers, what the common failure modes are, and what a realistic implementation looks like at different scales.
Companion piece to our broader work on AI in media and publishing — see AI in Media & Publishing: How to Retain Subscribers with Machine Learning for the strategic frame around recommendation, churn prevention, and reader retention; and our Media and Publishing industry overview for the broader picture of AI in publisher operations.
The Publisher Recommendation Problem Is Different
Before getting to architecture, it's worth being precise about what makes publisher recommendation distinct from entertainment recommendation.
Content turnover. A publisher producing 100 articles per day has a catalogue that is mostly new every 48 hours. Collaborative filtering — the technique that powers "users who liked X also liked Y" — requires enough user interactions with a piece of content to produce meaningful similarity signals. New content has zero interactions. The cold start problem, which is manageable in entertainment recommendation, is a near-permanent state for news.
Session structure. A subscriber visiting a news site spends 5–12 minutes per session, reads 1–3 articles, and may return three to five times per week. This is very different from a streaming user who watches a two-hour film in a single session. The implicit feedback signal from a news visit — a click, a scroll depth, a time-on-page — is weaker and more ambiguous than a film completion event.
Editorial intent. Publishers don't just want to maximise engagement with what readers already like. They want to expose readers to important stories they wouldn't seek out, support underperforming but high-quality journalism, and represent the full breadth of editorial coverage. Pure engagement optimisation produces filter bubbles and neglects public-interest journalism. This is not just an ethical concern — it's a commercial one, because readers who only receive content matching their existing interests are more likely to view the publication as redundant when they can get the same perspective elsewhere for free.
Conversion goals. For subscription publishers, recommendation is not purely an engagement function. It's a conversion function. The articles that are most likely to convert a registered user to a subscriber are not necessarily the same articles that maximise page views or time on site. A recommendation system optimised for engagement may actively work against subscription conversion if it surfaces free content rather than metered premium content.
The Three Approaches and When Each Works
Three architectural approaches dominate publisher recommendation: content-based filtering, collaborative filtering, and hybrid systems that combine the two. Each has distinct strengths, failure modes, and scale requirements — and the right choice depends on your audience size, content turnover, and editorial priorities. Most publishers progress through these approaches as they grow: content-based at small scale, collaborative or hybrid as the audience matures, and full two-stage retrieval/ranking architectures at production scale. The decision is rarely about which approach is "best" in the abstract — it's about which approach matches your data, your audience, and your editorial goals at your current stage.
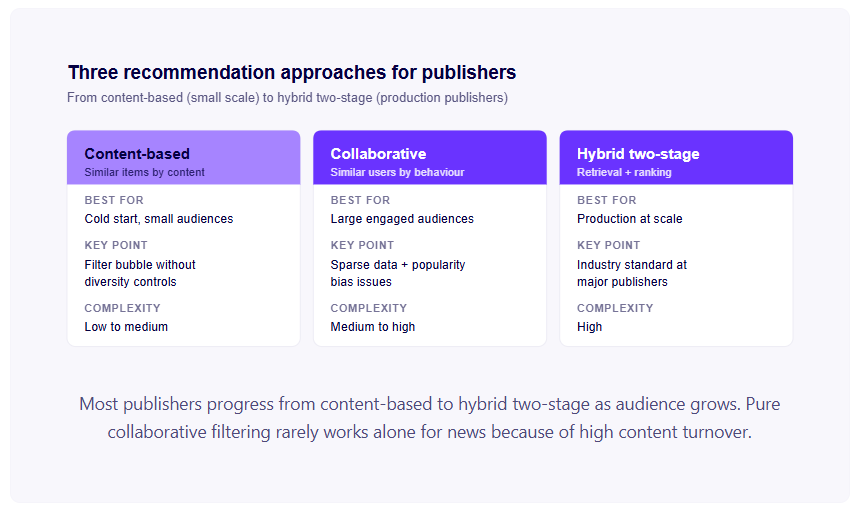
1. Content-Based Filtering
Content-based filtering recommends items similar to what a user has previously engaged with, based on the properties of the content itself rather than the behaviour of other users. For news, this typically means: text similarity (articles on similar topics, by similar authors, from similar sections), entity overlap (articles mentioning the same people, organisations, places), and recency weighting (more recent content scored higher).
When it works: Cold start situations — new users with no history, new content with no interaction data. Also effective for publishers with small audiences where collaborative filtering signals are too sparse.
When it fails: It produces a bubble. A reader who reads three articles about interest rates receives three more articles about interest rates. Content-based filtering has no mechanism for serendipity — for surfacing relevant content the user didn't know they wanted. It also doesn't capture the quality signals that engagement data provides: two articles on the same topic may have very different completion rates, share rates, and save rates, but content-based filtering treats them as equivalent.
Implementation complexity: Low to medium. Text embeddings (using pre-trained language models like Sentence-BERT or domain-fine-tuned versions) can produce reasonable content similarity scores without extensive ML infrastructure.
2. Collaborative Filtering
Collaborative filtering recommends based on the behaviour of similar users — "users who read what you read also read this." The core assumption: users with similar reading histories have similar preferences.
When it works: Mature sites with large, engaged audiences. Collaborative filtering needs enough interaction data — typically thousands of daily active users generating enough cross-article engagement signals — to produce meaningful user similarity clusters.
When it fails: Small audiences (insufficient signal), high content turnover (new articles have no collaborative signal), and for breaking news (all users are reading the same thing, producing no differentiation signal). It also amplifies popularity — popular content gets recommended more, gets more interactions, gets recommended more. Niche but important journalism gets buried.
Implementation complexity: Medium to high. Matrix factorisation approaches (ALS, SVD) are tractable but require infrastructure. Neural collaborative filtering (NCF) is more powerful but more complex to train and serve.
3. Hybrid Approaches
The models that work best in production for publishers combine content-based and collaborative signals with additional features: recency, user engagement signals (scroll depth, return visits, shares), article quality indicators (editor picks, engagement rate among similar users), and business rules (promote metered articles to registered users, surface subscription conversion prompts at high-propensity moments).
The two-stage architecture is the industry standard for publishers at scale:
Stage 1 — Retrieval: From the full content catalogue, quickly retrieve a candidate set of 50–200 articles that are plausibly relevant for this user. This stage prioritises recall over precision — better to include some irrelevant candidates than to miss relevant ones. Retrieval typically uses approximate nearest neighbour search on content embeddings, with collaborative filtering signals as a reranking layer.
Stage 2 — Ranking: From the candidate set, rank the articles to identify the 5–10 to present to the user. The ranking model incorporates more features than the retrieval stage: user history, session context (what they've read in the current visit), device type, time of day, business rules, and diversity constraints (don't recommend five articles on the same topic).
This architecture — used by the Guardian, Financial Times, Washington Post, and most sophisticated publishers — separates the tractability constraint (fast retrieval from a large catalogue) from the quality constraint (accurate, diverse ranking).
The Cold Start Solutions That Actually Work
The cold start problem — new content has no engagement data, new users have no history — requires specific design rather than hoping the main recommendation model handles it.
For new content: Assign initial recommendations based on section/topic (an article published in the Economics section gets recommended to users with Economics reading history), entity matching (articles mentioning specific people or companies get recommended to users who've read about those entities), and author following (for publishers where author loyalty is meaningful, new content by a followed author gets surfaced to followers immediately).
For new users: The registration funnel is an underused recommendation data source. Asking new users to select 3–5 topics of interest during registration — rather than just collecting an email address — produces an explicit preference signal that can seed recommendations from the first visit. Publishers that collect this data see materially better recommendation relevance in early sessions, which correlates with higher early engagement and lower early churn.
For anonymous visitors: Browser session context — what articles have been read in the current session — provides enough signal for basic session-based recommendation even without user identity. Transformer-based session recommendation models (BERT4Rec and variants) treat the current session's article sequence as a context and predict likely next articles. These work reasonably well for publishers with high anonymous traffic.
What Good Looks Like: The Metrics That Matter
Publishers evaluating recommendation quality often use the wrong metrics.
Click-through rate is the most commonly tracked recommendation metric. It's also the least useful. CTR measures whether users click on recommendations; it doesn't measure whether they read the recommended article, whether they found it valuable, or whether the recommendation contributed to their decision to subscribe.
Metrics that actually matter:
Article completion rate on recommended content — did users who clicked on a recommendation read the article to completion? Completion rate is a stronger signal of recommendation quality than click rate.
Return visit rate among users who engaged with recommendations — are users who engage with recommendations more likely to return? This connects recommendation quality to retention outcomes.
Subscription conversion rate on the recommended path — for subscription publishers, what's the conversion rate for users who arrive at the paywall via a recommendation versus organic navigation? Recommendation systems that surface premium content at high-propensity moments should show measurable conversion lift.
Serendipity and coverage — what proportion of the catalogue is being recommended? Are all sections, authors, and topics represented, or is recommendation concentrating on a small popular subset? Coverage metrics protect against recommendation systems that neglect important journalism.
Holdout measurement. Recommendation systems are hard to evaluate without a properly designed holdout — a control group of users who receive no personalised recommendations, or who receive a baseline (editorial curated list) instead. Without a holdout, it's difficult to establish whether recommendation is adding value beyond what users would find through navigation alone.
Common Failure Modes
Building the model before the data infrastructure. Recommendation models need user-level event data: what articles each user has read, when, for how long, with what engagement depth. Most publishers discover, after commissioning a recommendation system, that this data doesn't exist in a usable form — session data is in one system, user identity is in another, article metadata is in a third, and joining them requires data engineering that wasn't budgeted.
Optimising for the wrong metric. A recommendation system optimised for CTR produces articles with clickbait titles. A recommendation system optimised purely for completion rate surfaces comfortable long reads rather than news. The objective function needs to be a weighted combination of engagement signals and business outcomes (subscription conversion, return visit), with explicit diversity and editorial constraints.
Ignoring editorial intent. Fully automated recommendation without editorial override produces systems that editors don't trust and don't use. Building editorial control into the recommendation system — the ability to surface specific articles or series, to exclude articles from recommendation, to boost recent premium content — is not just a concession to editorial politics. It produces better recommendations because editors know things about content quality and importance that engagement signals don't capture.
Not measuring serendipity. The most commercially valuable thing a recommendation system can do for a subscription publisher is show a reader an article they didn't know they wanted from a section they wouldn't have navigated to — and have that article be so good it makes them value the subscription more. Systems that only optimise for relevance don't produce this. Diversity and novelty constraints in the ranking model are how you build it in.
What Implementation Looks Like at Different Scales
Under 100,000 monthly active users: A content-based system using text embeddings is probably the right starting point. The audience is too small for collaborative filtering signals to be meaningful. Focus data engineering on building the user-level event pipeline — you'll need it when you grow.
100,000 to 1 million MAU: A hybrid system becomes viable. Start with a two-stage architecture: content-based retrieval, engagement-signal reranking. This is implementable with a small data science team and reasonable infrastructure.
Over 1 million MAU: Collaborative filtering signals are meaningful. A full two-stage retrieval/ranking pipeline with user embeddings, content embeddings, and session context is justified. Real-time personalisation (updating recommendations as the user reads through a session) becomes achievable. Subscription propensity scores can be incorporated into the ranking model.
Three Modern Considerations: Privacy, LLMs, and Build vs Buy
Three considerations have become material for publisher recommendation in 2026 that weren't part of the standard playbook five years ago.
GDPR and profiling
Recommendation systems process personal data and constitute "profiling" under GDPR Article 4 — automated processing to evaluate user characteristics. For logged-in or registered users, processing requires a lawful basis (consent, contract performance, or legitimate interests under Article 6), with a right to object to profiling under Article 22 where the recommendation has significant effects. For anonymous users, cookie-based recommendation falls under ePrivacy/PECR rules — explicit consent is generally required for non-essential cookies including those used for personalisation.
The 2024–2025 enforcement environment for cookie-based profiling has tightened materially. New recommendation systems should be designed against current enforcement expectations rather than the looser 2020 baseline most publishers built against. Where consent is the legal basis, the recommendation system needs to handle the absence of consent gracefully — falling back to editorial curation or non-personalised popularity-based recommendation for users who decline tracking.
LLMs as recommendation components
Large language models have become useful components in recommendation systems but not replacements for traditional infrastructure. Effective uses in 2026:
- Generating high-quality content embeddings — replacing or augmenting Sentence-BERT in the retrieval stage with LLM-derived embeddings that capture more nuanced content similarity.
- Reranking candidate recommendations using LLM-based scoring with explicit editorial criteria — for example, asking the LLM to rank candidates by "would this article surprise a reader who already cares about X?"
- Generating personalised explanations for why an article was recommended ("because you read about interest rates last week"), which materially improves user trust in the recommendations.
- Zero-shot recommendation for cold-start users based on natural-language interest descriptions captured during registration.
Ineffective uses: replacing the full recommendation pipeline with an LLM. The latency, cost, and reliability profile doesn't yet match traditional models for high-volume real-time recommendation. The 2026 pattern is hybrid — traditional models for hot-path inference, LLMs for offline candidate generation, explanations, and edge cases.
Vendor vs build
Many publishers buy recommendation infrastructure rather than build it. Vendors at different points: Outbrain and Taboola for content recirculation and traffic monetisation; Recombee, RTB House, and similar for general-purpose personalisation; Piano and Sailthru-class tools for subscription-focused recommendation and lifecycle marketing.
Vendors are faster to deploy and lower upfront cost — useful for publishers under 1M MAU where recommendation isn't a strategic differentiator. Build is right when recommendation is core to your product strategy, when you have a meaningful data science capability, and when your editorial requirements (diversity, conversion optimisation, premium content surfacing) don't fit a vendor's standard configuration. The hybrid pattern — build the ranking layer with custom editorial features, buy the retrieval infrastructure — is increasingly common at mid-scale publishers.
The publishers that get recommendation right aren't the ones with the most sophisticated models. They're the ones who built the data infrastructure first, picked the right metrics second, and kept editorial control through the loop.
Conclusion: What Publishers Should Do Next
Publisher recommendation is one of the higher-leverage AI investments available to digital publishers — but the leverage is conditional on getting the implementation right. The systems that succeed share three structural features: data infrastructure built before models, metrics that reflect business outcomes rather than vanity engagement, and editorial control preserved in the loop. The systems that fail share a different pattern: a focus on model sophistication while data quality, metric design, and editorial integration are treated as afterthoughts.
For publishers evaluating a recommendation investment in 2026, three practical recommendations:
- Audit your data first. Before commissioning a recommendation system, verify that user-level event data — joining session data to user identity to article metadata — is available and queryable. If not, that engineering is your first project, not your second.
- Pick the metric before the model. Decide what success looks like (completion rate, return visit rate, subscription conversion, coverage) and build the measurement infrastructure — including a holdout — before you train. CTR-by-default is the most common reason recommendation systems fail commercially.
- Match the architecture to scale. Don't build collaborative filtering for a 50K MAU audience. Don't deploy a content-based system alone at 5M MAU. The right architecture is a function of your audience size, your content turnover, and your editorial goals — not the latest research paper.
The publishers that win on recommendation have an unfair advantage available: most generic recommendation vendors treat publishers like e-commerce sites and underperform as a result. Building — or carefully customising — recommendation against the actual structure of news consumption (high content turnover, weak implicit feedback, editorial intent, subscription conversion goals) is a genuine commercial moat. The work is harder than picking a vendor and switching it on; the upside, done well, is materially better engagement, retention, and subscription conversion than what's available off the shelf.
Where Vector Labs Fits
Vector Labs builds recommendation and personalisation systems for digital publishers, including subscription conversion optimisation and reader retention AI. We work with publishers at three points: scoping (audience scale assessment, build/buy decisions, metric design), data infrastructure (event pipeline, user profile construction, content metadata, A/B testing infrastructure), and modelling (two-stage retrieval/ranking, LLM integration, diversity and editorial controls, real-time personalisation).
If you're evaluating a recommendation investment and want to understand what's right for your scale, get in touch at vector-labs.ai.
For related work, see our broader piece on AI in Media & Publishing: How to Retain Subscribers with Machine Learning, or our Media and Publishing industry overview.
FAQs
Roughly 100,000+ monthly active users with meaningful daily engagement is the practical floor for collaborative filtering signals to be reliable. Below that, the user-item interaction matrix is too sparse to produce stable similarity clusters, and you're better served by content-based or hybrid approaches that don't require dense interaction data. Above 100K MAU, hybrid models become viable; above 1M MAU, pure collaborative filtering and user-embedding approaches start to dominate. The number depends on engagement depth — a 100K MAU site where most users read one article per visit has weaker collaborative signal than a 50K MAU site where users read five.
Depends on scale, differentiation, and engineering capacity. Vendors (Recombee, Outbrain, Taboola, RTB House, Piano, Sailthru) are faster to deploy and lower upfront cost — useful for publishers under 1M MAU or where recommendation isn't a strategic differentiator. Build is right when recommendation is core to your product strategy, when you have a meaningful data science capability, and when your editorial requirements don't fit a vendor's standard configuration. The hybrid pattern — build the ranking layer and key custom features, buy the retrieval infrastructure — is increasingly common at mid-scale publishers.
Four metrics that matter more than CTR. Article completion rate on recommended content (did users read the article they clicked?), return visit rate among users who engage with recommendations (does engagement correlate with retention?), subscription conversion rate via the recommended path (for subscription publishers, recommendation should drive conversions), and coverage and serendipity (what proportion of your catalogue is being recommended? Are all sections represented?). Pair these with a proper holdout — users who receive no personalised recommendations or a baseline list — to establish whether your system is adding value over default navigation.
Yes. Recommendation systems process personal data and typically involve "profiling" under GDPR Article 4 — automated processing to evaluate user characteristics. For logged-in or registered users, processing is on the basis of consent, contract performance, or legitimate interests, with the user's right to object to profiling under Article 22 where the recommendation has significant effects. For anonymous users, cookie-based recommendation falls under ePrivacy/PECR rules — explicit consent is generally required for non-essential cookies including those used for personalisation. The 2024–2025 enforcement environment for cookie-based profiling has tightened materially; new recommendation systems should be designed against current enforcement expectations.
For specific use cases, yes — LLMs are now a useful component but not a replacement for traditional recommendation infrastructure. Effective uses include generating high-quality content embeddings (replacing or augmenting Sentence-BERT), reranking candidate recommendations using LLM-based scoring with editorial criteria, generating personalised explanations for why an article was recommended, and zero-shot recommendation for cold-start users based on natural-language interest descriptions. Ineffective uses include replacing the full recommendation pipeline with an LLM — the latency, cost, and reliability profile doesn't yet match traditional models for high-volume real-time recommendation.
Three concrete approaches. Diversity constraints in the ranking model — explicitly require that the top N recommendations span M different sections, topics, or viewpoints. Serendipity injection — periodically include a recommendation that scores moderately on relevance but high on novelty, exposing the user to content outside their established pattern. Editorial overrides — allow editors to mark articles as "must surface" regardless of relevance score, ensuring public-interest journalism reaches readers who wouldn't seek it out. Measure coverage — what proportion of your catalogue is being recommended week over week — and treat low coverage as a quality signal to address.
Batch recommendation generates recommendations periodically (typically nightly) using accumulated user data, then serves the same recommendations to a user until the next batch. Cheap and simple — appropriate when user behaviour is relatively stable session-to-session. Real-time recommendation generates recommendations dynamically based on current session context — articles the user has read in this visit, current trending content, time of day. More expensive (lower latency requirements, online inference infrastructure) but materially better for news, where what the user wants depends on what's happening right now. Most publishers run hybrid: batch-generated user profiles updated nightly, real-time scoring based on session context.
Three structural patterns. First, holdout: a control group receives no personalised recommendations (or a baseline editorial list). Compare engagement, retention, and conversion between holdout and personalised groups. Second, multi-arm bandit: test multiple recommendation variants simultaneously, allocating traffic to better-performing variants dynamically. Useful for ranking model variations. Third, switchback: alternate the recommendation system between variants over time periods. Each has trade-offs; for foundational measurement (is recommendation working at all), a long-running holdout is essential. Without it, you can optimise the system endlessly without knowing whether it's adding value.