Almost every major news publisher has announced a personalisation strategy. Almost none of them have delivered one that works.
The announcements follow a predictable pattern. A chief product officer presents a vision: AI that learns each reader's interests, surfaces the stories most relevant to them, and creates a reading experience that feels like a publication edited specifically for that person. There is a partnership announcement with a technology vendor, a case study from a different industry, and a roadmap with ambitious milestones.
Twelve months later, the personalisation initiative is producing "Most Read" lists and topic follow buttons. Maybe a "For You" section that recirculates the publication's own popular content. Sometimes a newsletters product with self-selected preferences. The vision persists. The delivery doesn't.
This article is about why that gap exists — the specific technical, organisational, and editorial reasons that news personalisation consistently underdelivers — and what publishers who are serious about it need to approach differently.
Companion piece to our broader work on AI in media and publishing. See Content Recommender Systems for Publishers for the recommendation infrastructure that sits underneath personalisation, The Paywall Optimisation Problem for how personalisation drives subscription conversion, Audience Segmentation Beyond Demographics for the behavioural ML that feeds personalisation, AI in Media & Publishing: How to Retain Subscribers with Machine Learning for the strategic frame, and our Media and Publishing industry overview for the broader picture.
What Personalisation Actually Means (and What It Doesn't)
Part of the problem is definitional. "Personalisation" in publishing has become a catch-all term that covers at least four distinct things, which require different technology, different data, and different organisational capability.
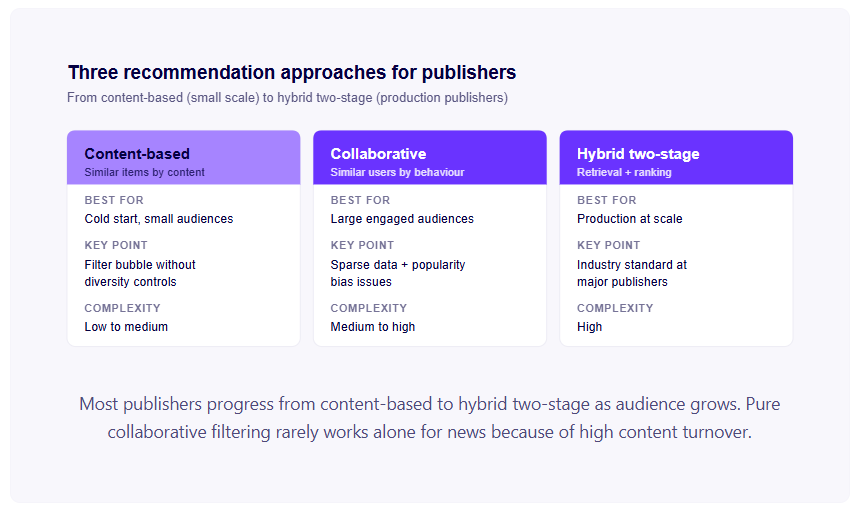
Content recommendation — surfacing articles a reader hasn't seen but is likely to find relevant, based on their reading history. This is the Netflix comparison. It requires behavioural data, a recommendation model, and a placement in the reading journey where recommendations are shown.
Homepage personalisation — customising the order, selection, or presentation of content on the main entry point of a publication based on individual reader history. This is more complex than article-level recommendation because the homepage is also an editorial statement about what the publication considers important. The tension between editorial curation and personalisation is most acute here.
Push notification personalisation — sending readers alerts about stories they specifically care about rather than the same breaking news alert to the entire subscriber base. Requires topic modelling, reader preference profiles, and a notification delivery system capable of individual-level targeting.
Offer and subscription personalisation — showing different subscription offers, prices, or trial structures to different readers based on their engagement profile and predicted conversion propensity. This is paywall optimisation but is often grouped under the personalisation umbrella.
Most publishers who announce a "personalisation strategy" are conflating these four things, which means they're trying to do all of them at once with inadequate data infrastructure and a team that hasn't decided which one to prioritise. The result is partial implementation of all four and effective delivery of none.
The Technical Reasons It Fails
The Identity Problem
Personalisation requires knowing who is reading. The majority of news website traffic is anonymous — users not logged in, sometimes not even cookied, arriving from search or social with no persistent identity. The proportion of traffic that can be personalised from day one is often 10–30% of total visits.
For the anonymous majority, personalisation can be session-based (responsive to what the user has read in the current session) but not user-based (responsive to the user's full history). Session-based personalisation using transformer models trained on article sequences has improved significantly and can produce meaningful recommendations. But it's structurally less powerful than history-based personalisation for a user with a year of reading history.
The fundamental response to the identity problem — getting more users registered and logged in — requires a value exchange. The publication offers something valuable enough that the reader provides an email address and creates an account. Newsletters, personalised email digests, exclusive content, and saved articles have all been used effectively as registration incentives. Publishers who invest in registration grow the addressable population for personalisation.
The Data Pipeline Gap
User-level personalisation requires user-level event data at sufficient granularity. This means: every article read by every user, with timestamps, engagement depth signals (scroll, time on page), and device context, stored in a form that can be joined to user profiles and queried by a real-time recommendation system.
Most publishers don't have this pipeline. They have:
- Google Analytics or a similar aggregate analytics tool that provides audience-level metrics but not user-level event histories
- A CMS with article metadata but not linked to reader behaviour
- A subscription management platform with subscriber records but not linked to reading behaviour
- A CRM with email engagement data but not linked to on-site reading behaviour
Building the data infrastructure to join these systems — a Customer Data Platform (CDP) or a custom event pipeline — is typically a 6–12 month engineering project before any personalisation model can be built. This is the phase that most personalisation announcements skip over. It's also the phase where most personalisation initiatives actually stall.
The Cold Start Volume Problem
Even with a working data pipeline, the cold start problem is severe for news personalisation. A user who has read 10 articles doesn't have enough history to produce reliable preference signals. With seasonal content cycles, major news events that draw readers who don't normally engage with a topic, and the high proportion of users who visit infrequently, a large share of any publication's active readership will be in a near-cold-start state at any given moment.
The content cold start problem compounds this. An article published this morning has no engagement history. Content-based signals (topic, entity, author) can route it to relevant users, but engagement-based signals that would improve routing won't exist until it has been read by enough users to generate them. For news publications where the most valuable content is often the most recent, this is a structural constraint.
The Editorial Reasons It Fails
The Filter Bubble Problem (And Why Editors Are Right to Worry About It)
Every news editor who has been asked about personalisation raises the filter bubble concern: if readers only see content matching their stated interests, they'll never encounter the important stories they didn't know they cared about, the perspectives that challenge their existing views, or the public-interest journalism that the publication considers part of its civic responsibility.
This is a legitimate concern, and it's often dismissed too quickly by product teams who respond with "we'll add diversity constraints to the algorithm." Diversity constraints help, but they don't resolve the underlying tension. An algorithm optimised for relevance — even with diversity constraints — will systematically underweight the serendipitous discovery of important but personally unfamiliar stories. And it will do so invisibly, producing a personalised experience that readers perceive as better without realising what they're not seeing.
The publications that have navigated this most thoughtfully — The Financial Times, The Guardian — treat personalisation as a supplementary layer rather than a replacement for editorial curation. The main homepage remains editorially curated. Personalisation operates in specific contexts (the "For You" section, the newsletter digest, the post-article recommendation module) where its scope is bounded and its interaction with editorial judgement is clear.
The Measurement Problem
Publishing organisations find it genuinely difficult to measure whether personalisation is improving the reader experience. Engagement metrics (page views, time on site, article completion rates) are easy to measure but don't capture whether a reader feels better served. Subscriber retention is the most commercially meaningful outcome but has a long feedback loop — the effect of personalisation on churn may not be measurable for 12–18 months at the subscriber cohort level.
Without clear measurement of value, personalisation programmes struggle to justify continued investment. When the product team reports that the "For You" section has 12% click-through rate versus 8% for the standard recommendation module, that sounds positive — but it doesn't tell the business whether personalisation is reducing churn, increasing subscription value, or improving reader satisfaction in ways that matter commercially.
What Successful Personalisation Actually Looks Like
The publishers that have actually delivered meaningful personalisation share several characteristics that distinguish them from the majority:
They started with a single, well-defined use case. Not "personalise the publication" — "reduce unsubscribe rates from our daily newsletter by surfacing the three articles most relevant to each subscriber's reading history." A single, measurable use case with a clear data requirement and a clear success metric. This produces actual delivery rather than perpetual roadmap.
They solved identity before personalisation. They invested in registration growth — giving readers specific, valuable reasons to log in — before investing in personalisation infrastructure. The result is a larger addressable population from which the personalisation infrastructure can learn.
They treated editorial buy-in as a prerequisite. Personalisation initiatives that were launched as technology projects without editorial team involvement consistently failed to reach meaningful scale. Editors who don't understand and trust the algorithm refuse to let it touch the homepage, limit its scope to low-traffic sections, and use it as a scapegoat when engagement metrics disappoint. Personalisation that has editorial champions — editors who see the audience intelligence the system produces and find it useful — gets iterated on and improved.
They measured against the right outcomes. Not click-through rate on the "For You" module — subscriber retention rate for the cohort of subscribers who engage with personalised features versus those who don't, with a properly randomised holdout.
Privacy, the Cookieless Future, and LLMs
Three considerations have become material for news personalisation in 2026 that weren't part of the standard playbook five years ago.
GDPR and profiling
News personalisation processes personal data and constitutes "profiling" under GDPR Article 4. For logged-in users, processing requires a lawful basis (consent, contract, or legitimate interests). For anonymous users, cookie-based personalisation falls under ePrivacy/PECR rules with explicit consent for non-essential cookies. Article 22 gives users the right to object to profiling with significant effects, particularly relevant where personalisation drives offers, pricing, or content access. The practical implications: document the personalisation logic in your privacy notice, run a DPIA before launch, and design the system to operate gracefully when users decline consent — falling back to editorial curation rather than failing.
The cookieless future
Third-party cookie deprecation has been moving through Safari, Firefox, and increasingly Chrome. For news personalisation specifically — which depends heavily on identifying anonymous returning readers — the implications are structural. Without third-party cookies, cross-domain identification weakens, and the addressable anonymous population for personalisation shrinks. The publishers best positioned for this shift are those who built first-party data strategies early — registration funnels, newsletter signups, logged-in sessions. First-party data is now the foundation, not a complement to third-party tracking.
LLMs in news personalisation
Large language models have become useful components in the personalisation stack — not as replacements for traditional infrastructure, but for specific high-value applications. Effective uses: generating personalised newsletter content (summaries tailored to a reader's interests, generated from the day's articles), per-user content recommendations with natural-language explanations of why each article was suggested, generative editorial briefs for engagement teams ("readers in segment X engaged most with these themes this week"), and cold-start recommendations using natural-language interest descriptions captured during registration. Less effective: replacing the core recommendation engine with an LLM — traditional ML approaches remain more efficient for high-volume real-time inference. The 2026 pattern is hybrid: traditional models for hot-path recommendation, LLMs for content generation, explanations, and edge cases.
The publishers that deliver personalisation that works aren't the ones with the most ambitious announcements. They're the ones who picked one use case, solved the identity and data problems first, and treated editorial buy-in as a prerequisite — not an obstacle.
Conclusion: What Publishers Should Do Next
The gap between personalisation promised and personalisation delivered is one of the most consistent patterns in digital publishing. The cause is rarely the technology — recommendation models, segmentation infrastructure, and CDP-based event pipelines are all well-understood. The cause is almost always the same combination of factors: scope ambiguity, identity gap, data infrastructure not in place, editorial buy-in not secured, and measurement that doesn't connect to commercial outcomes.
Three practical recommendations for publishers planning a personalisation investment in 2026:
- Pick one use case and define it precisely. Not "personalise the publication" — "increase newsletter open-to-click conversion by 25% within 12 months using per-recipient article selection from the daily newsletter." A specific use case with a clear data requirement, a clear success metric, and a clear team accountable. The minute the scope expands beyond one use case, the project starts to fail.
- Solve identity and data infrastructure before you commission a model. Audit the registration funnel, the event pipeline, the CDP, the integration to downstream systems. If any of these isn't in place, fix it first. A perfectly tuned recommendation model on a broken data pipeline is worth nothing.
- Recruit editorial champions before launching. Identify the editors who are willing to engage with the system, give them operational control (override, exclude, boost), and share the audience intelligence the system produces. Personalisation that has editorial champions gets iterated; personalisation that editors don't trust gets cornered into low-traffic modules and fades.
The publishers that deliver personalisation are the ones who treat it as an operational capability built in stages, not a product announcement made in a press release. The technology is increasingly commoditised. The operational discipline — scope, identity, infrastructure, editorial integration, measurement — is what separates publishers that ship personalisation from publishers that announce it.
Where Vector Labs Fits
Vector Labs builds personalisation and recommendation systems for subscription publishers, grounded in the data infrastructure and editorial workflow integration that determines whether personalisation actually works. We work with publishers at three points: scoping (use case selection, identity strategy, build/buy decisions, success-metric design), data infrastructure (CDP integration, event pipeline, first-party data strategy, cookieless transition), and modelling (recommendation engines, real-time scoring, LLM integration, editorial control layer, segment-level A/B testing).
If you're planning a personalisation investment, let's start with the honest conversation about what it requires.
For related work, see our companion articles on Content Recommender Systems for Publishers for the underlying recommendation infrastructure, The Paywall Optimisation Problem for how personalisation drives subscription conversion, Audience Segmentation Beyond Demographics for the behavioural ML that feeds personalisation, our broader piece on AI in Media & Publishing: How to Retain Subscribers with Machine Learning, and our Media and Publishing industry overview.





