



The data problem in healthcare AI: how to train a clinical-grade model when you don't have enough patients


Healthcare AI has a data paradox. The domain generates more data than almost any other. Еvery clinical interaction, every scan, every lab result, every vital sign produces structured and unstructured data at scale. And yet the data needed to train a specific clinical AI model for a specific indication in a specific patient population is almost always scarce.
The reasons are structural. Patient privacy restrictions make centralising data legally difficult. Rare conditions mean small patient volumes by definition. Historical data is often in formats unsuitable for ML training, scanned paper records, free text, inconsistent coding. And the data that does exist is often imbalanced: many negative examples (no disease), few positive examples (confirmed disease), with the positive examples being exactly what the model needs to learn from.
Founders building healthcare AI face this problem in almost every project. This article covers the practical strategies that actually work, not the theoretical ones, but the ones we've used to build clinical-grade models when the obvious training data didn't exist.
Why "get more data" is not a strategy
The reflex response to data scarcity — collect more data — is often not available on the timescales that matter for a startup.
A prospective data collection study requires IRB or ethics approval (6–12 months), clinical site setup and contracting (3–6 months per site), patient recruitment and data collection (months to years depending on incidence), data cleaning and labelling (weeks to months), and validation dataset holdout before any training data is available for your model. For a rare condition with an incidence of 1 in 10,000, a prospective study to collect 500 cases might take a decade.
This doesn't mean prospective data collection is wrong. It's the gold standard, and for a commercial-scale product, eventually necessary. It means that for the prototype, the pilot, and the initial CE mark or FDA submission, you need strategies that work with the data you have or can access on a 12–24 month timeline.
Six strategies that work
Six practical strategies cover the data-scarcity space for clinical AI. Most successful programs use multiple strategies in combination, transfer learning plus weak supervision plus synthetic augmentation, for example, rather than relying on any single technique.
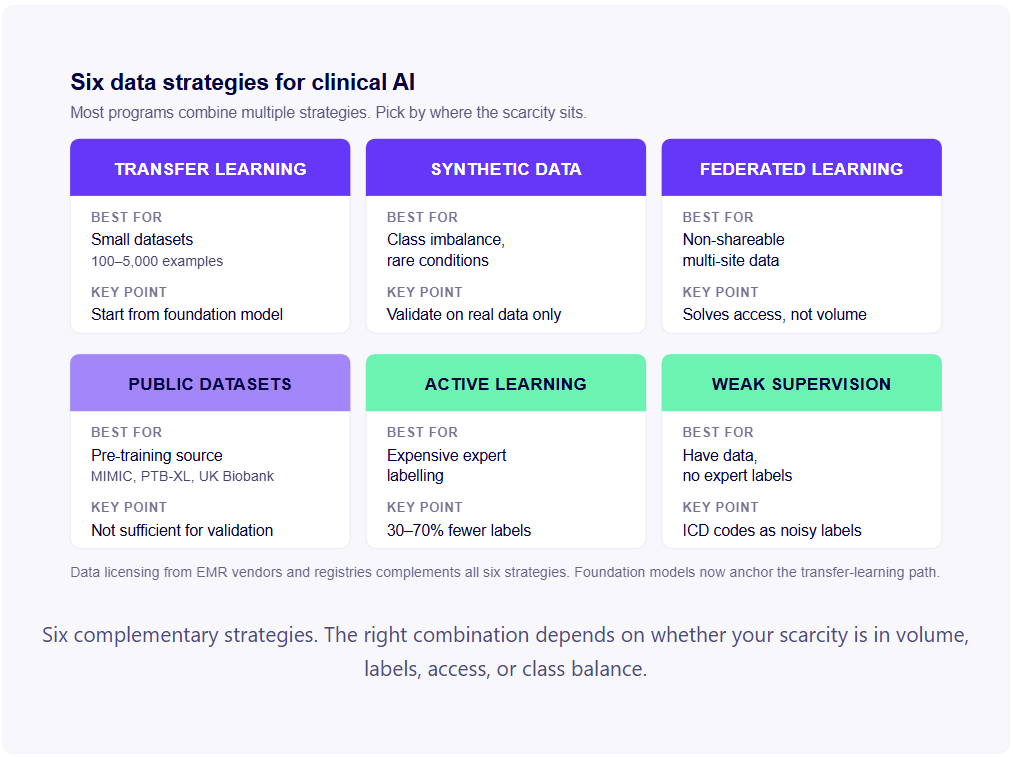
Transfer learning and medical foundation models
Transfer learning is the technique of initialising a model with weights pre-trained on a large, related dataset before fine-tuning on your smaller, specific dataset. Until recently, this typically meant starting from a model pre-trained on ImageNet (for vision) or a general-purpose language model like BERT (for NLP), with task-specific medical fine-tuning afterwards.
That has shifted significantly over the past two years. The dominant pattern in 2025–2026 is to start from a medical foundation model trained specifically on biomedical or clinical data:
- Medical imaging: MedSAM (medical image segmentation), BioMedCLIP (biomedical image–text), RadFM (radiology foundation model), and increasingly domain-specific models for pathology, dermatology, and ophthalmology.
- Clinical signals: Pre-trained ECG transformers (ECG-FM, HeartBEiT) and physiological signal foundation models, typically trained on tens of millions of unlabelled signals from public and consortium datasets.
- Clinical text and structured data: BioBERT, PubMedBERT, ClinicalBERT, and biomedical-tuned large language models like MedGemma, BioMistral, and the Med-PaLM family.
The practical effect: where a clinical-grade model used to require 10,000+ labelled examples trained from scratch, fine-tuning a medical foundation model can produce comparable performance with 1,000–5,000 examples and in some emerging zero-shot and few-shot scenarios, even less. The foundation model has already learned the general structure of the domain; your fine-tuning specialises it.
For KARDI AI's cardiac diagnostic work, pre-trained ECG representation models initialised on large public ECG datasets provided the starting point for fine-tuning on the specific cardiac conditions of interest. The pre-trained representations captured general ECG morphology; the fine-tuning specialised them for the target clinical question.
The regulatory implication: your pre-training source matters and needs to be documented in the regulatory submission. Foundation models trained on data with unclear provenance, biased composition, or unverifiable quality create regulatory exposure that's hard to mitigate later. Choose foundation models with documented training data and published evaluation, and disclose the choice explicitly in your technical file.
Synthetic data augmentation
Synthetic data generation uses generative models to produce artificial training examples that mimic real clinical data. The goal is to augment a small real dataset with synthetic examples, effectively increasing the training set size without collecting additional patient data.
For medical imaging: Generative Adversarial Networks (GANs) and diffusion models have been used to generate synthetic CT scans, MRI images, and histopathology slides. The key requirement is that the synthetic images need to be both realistic (indistinguishable from real images to the model) and diverse (not just copies of the training images with minor perturbations).
The regulatory consideration is significant: if synthetic data is used in training, it needs to be disclosed in your regulatory submission, and the notified body or FDA will expect evidence that the synthetic data is realistic and that training on synthetic data doesn't introduce systematic biases or performance artefacts. The validation dataset must be entirely real. Using synthetic data for validation is not acceptable.
For structured clinical data: Variational Autoencoders (VAEs) and Gaussian copula methods can generate synthetic patient records that preserve the statistical structure of the real data (correlations between variables, marginal distributions) without including actual patient records. This is particularly useful for privacy-preserving data sharing — sharing synthetic patient datasets that carry no individual patient privacy risk while training models that generalise to the real population.
For tabular data with class imbalance: SMOTE (Synthetic Minority Oversampling Technique) and its variants generate synthetic examples of the minority class, typically positive disease cases, by interpolating between existing minority class examples in feature space. Less powerful than full generative models but computationally simpler and well-established in the regulatory literature.
The limitation of all synthetic approaches: the model learns to generalise to the real data distribution only if the synthetic data accurately represents that distribution. If your generative model has mode collapse (produces only a subset of real data diversity) or introduces systematic artefacts, your model trains on a biased synthetic dataset and the performance on real data will be worse than the synthetic validation suggests.
Federated learning
Federated learning distributes model training across multiple data sources without centralising the data. Each site trains locally; only model updates (not patient data) are shared. The practical outcome is a model trained on the combined data of multiple sites, with the privacy guarantees that come from data never leaving each institution.
For healthcare AI data scarcity, federated learning is most valuable in two scenarios:
Small patient volume per site, but multiple sites. For rare diseases or uncommon presentations, any single hospital might have 50–100 cases in its records. Federated training across 10 hospitals gives you access to 500–1,000 cases — potentially enough for a meaningful model — without the legal and logistical burden of centralising the data.
Legally or practically non-shareable data. Where data sharing agreements are unavailable, regulatory frameworks prohibit centralisation, or institutional governance prevents data export, federated learning may be the only route to multi-site training.
Federated learning solves a data access problem, not a data volume problem. If the aggregate dataset across all federated sites is too small for the task, federated learning doesn't change that.
The limitations are real — non-IID data distributions across sites, communication overhead, and performance degradation from gradient noise — and they need to be addressed in the federated architecture and characterised in the regulatory submission.
External datasets and pre-competitive data sharing
Several large public medical datasets are available for training healthcare AI models, and pre-competitive data sharing — where multiple competing companies share access to training data — has matured significantly over the past five years.
Useful public medical datasets:
- MIMIC-IV: 300,000+ ICU admissions at Beth Israel Deaconess Medical Center; structured EHR data and clinical notes. Requires a credentialled data use agreement and widely used for clinical prediction models.
- PhysioNet: Large collection of physiological signal datasets including ECG datasets (PTB-XL with 21,837 ECG records), EEG data, and clinical time series.
- The Cancer Genome Atlas (TCGA): Genomic and clinical data for 33 cancer types; extensively used for oncology AI.
- UK Biobank: 500,000 participant cohort with genetic, imaging, and health record data; access via approved research application.
- NIH Chest X-ray dataset: 112,000 chest X-ray images with disease labels; widely used for thoracic imaging AI.
- Retinal imaging datasets: Kaggle diabetic retinopathy dataset, IDRiD, Messidor-2.
- Genomic and biobank consortia: All of Us (US), FinnGen (Finland), Estonian Biobank, deCODE (Iceland) — variable access conditions but substantial scale.
The practical use of public datasets: they're most valuable as pre-training or transfer learning sources — using a public dataset to initialise a model that is then fine-tuned on your proprietary clinical data. Using a public dataset as your primary validation dataset is generally not acceptable for regulatory submissions, because the patient population and acquisition conditions don't match your intended use.
Pre-competitive data sharing in life sciences runs through initiatives like the European Health Data Space (EHDS), the OHDSI/OMOP consortium (standardised observational data across 130+ data partners), various national health data partnerships, and disease-specific consortia. For startups targeting specific clinical domains, engaging with these initiatives early — even as a collaborator rather than a lead — provides access to training data that would otherwise require years of prospective collection.
Active learning
If your bottleneck is not data but labelled data — you have clinical records but annotating them requires expensive clinical expert time — active learning reduces the labelling cost by selecting which cases to label.
The active learning approach: train an initial model on a small labelled seed dataset. Use the model to predict on the unlabelled pool. Identify the cases the model is most uncertain about (typically measured by prediction entropy or margin between the top two class probabilities). Prioritise those cases for expert labelling. Retrain. Repeat.
The principle: the model learns most from the cases it's most uncertain about. Random selection of cases to label wastes annotation budget on cases where the model's prediction would have been correct regardless. Active learning concentrates annotation effort where it produces the largest performance gain.
Published research suggests active learning can achieve equivalent model performance to passive random sampling with 30–70% fewer labelled examples, depending on the task and the initial dataset. In clinical AI, where expert annotation can cost £50–£200 per case (radiologist or specialist time), a 50% reduction in labelling requirements is significant — for a 5,000-case dataset, that's £125K–£500K saved.
The limitation: active learning works within the distribution of the unlabelled pool. If your unlabelled pool doesn't include rare but important clinical presentations, active learning won't help you acquire labels for them — it selects from what's available.
Weak supervision and programmatic labelling
Traditional supervised learning requires expert-labelled examples. For clinical AI, expert labelling is expensive and slow. Weak supervision uses lower-cost, lower-accuracy label sources — clinical codes, report text, structured templates, rule-based heuristics — to generate noisy labels that can be used to train an initial model.
The classic application: using ICD diagnostic codes from EHR records as training labels. If a patient's EHR contains an ICD code for atrial fibrillation, that's a (noisy) positive label for a model predicting AF from ECG or physiological data. The codes are imperfect — coding errors, coding lag, missed diagnoses — but over a large enough dataset, the signal outweighs the noise.
The Snorkel framework and similar programmatic labelling tools allow combining multiple weak label sources — diagnostic codes, clinical text patterns, structured templates, domain rules — into a probabilistic label model. The label model's outputs are then used to train a downstream ML model. This approach has been used to train clinical prediction models at scale at Stanford, Google Health, and major academic medical centres.
For regulatory submissions: models trained on weakly supervised labels require particularly careful validation on expert-labelled holdout sets, with transparent disclosure of the labelling methodology and analysis of label noise effects on model performance.
Data licensing as a complementary path
A path that doesn't get enough attention in technical literature but is increasingly common in commercial practice: licensing clinical data from EMR vendors, health data platforms, and registries.
The major commercial sources:
- EMR vendors: Epic (Cosmos research network), Oracle Health (formerly Cerner), Allscripts. Aggregated de-identified records across thousands of sites, typically licensed for research and product development.
- Health data platforms: TriNetX, Komodo Health, IQVIA, Truveta. Network access to longitudinal clinical data from health system partners.
- Disease-specific registries: Often academic-led, varying access conditions. Strong for rare conditions where commercial sources are weak.
Cost ranges from €100K to €1M+ per license, depending on scope (specific condition vs broader network), exclusivity, and intended use. The constraints are real: re-identification risk requires strict handling protocols, de-identification standards may not match your specific clinical use case, and commercial deployment typically requires license renegotiation. Most useful for development and pre-training; less reliable for primary validation data, which usually needs to come from your own clinical partnerships.
The EU AI Act layer for training data
For EU-bound programs, the AI Act adds specific training data governance requirements on top of MDR's clinical evaluation expectations. As of August 2026, with high-risk AI provisions in force, these requirements are operative.
The relevant obligations for training data:
- Data quality and relevance: documented evidence that training, validation, and testing data are relevant, representative, and free of obvious errors for the intended use.
- Statistical properties: analysis of training data statistical properties, including bias testing across relevant subgroups (age, sex, ethnicity, comorbidity).
- Data governance practices: documented data collection and preparation processes, including labelling methodology, and the choices made about pre-processing.
- Privacy and rights protection: alignment with GDPR data minimisation, consent, and special-category protections.
The practical implication: data documentation that was acceptable for MDR alone may need to be expanded for AI Act conformity. The choice of foundation model, the use of synthetic augmentation, the federated learning architecture, the data licensing terms, and the labelling methodology all need to be documented to a higher standard than was previously typical. Programs already through MDR conformity assessment have a meaningful head start; new entrants must plan AI Act training-data documentation from week one.
Building a data strategy before you build a model
The practical implication of all of the above: your data strategy should be designed before your model architecture. The model you can build depends on the data you can access and label. Designing the model first and then discovering the data doesn't exist produces the "twelve months in with nothing to train on" situation that ends projects.
A data strategy for a healthcare AI startup should cover:
- What training data is accessible now (public datasets, foundation models, institutional partners, existing records, licensed sources)?
- What data can be acquired in 6–12 months (federated partners, ethics-approved prospective collection, commercial licensing)?
- What augmentation strategies are appropriate for your data type and regulatory pathway?
- What is the minimum dataset size required for the performance level your intended use requires?
- How will the validation dataset be kept fully independent from all training data, including augmented, synthetic, and pre-training data?
- How will the data strategy be documented for both MDR clinical evaluation and AI Act conformity?
This is the conversation to have before the engineering starts. It determines the timeline, the cost, and whether the regulatory submission you're planning is achievable on your current roadmap.
FAQs
There's no universal number. It depends on task complexity, signal-to-noise ratio, and the performance level your intended use requires. Rough rules of thumb: for binary classification with transfer learning from a relevant medical foundation model, 1,000–5,000 labelled examples can produce a credible Class IIa system. Without transfer learning, 10,000+ examples are typically needed. For rare conditions, targeted enrichment to reach 50–100 confirmed positive cases per condition is the typical lower bound for credible performance estimates.
Yes, and this is standard practice in 2025–2026. Medical foundation models — MedSAM, BioMedCLIP, RadFM, MedGemma, biomedical language models like BioBERT and PubMedBERT — provide pre-trained representations that dramatically reduce the data needed for fine-tuning. Foundation models also drive emerging zero-shot and few-shot performance for clinical tasks. Regulatory documentation needs to disclose the pre-training source and explain how the foundation model was used.
For training, yes, when properly disclosed and characterised. Notified bodies and FDA increasingly accept synthetic data as a training augmentation, provided you document the generation methodology, validate that synthetic samples preserve clinically relevant features, and demonstrate that the model generalises to real data. For validation, no, your validation dataset must be entirely real clinical data. Synthetic validation results don't predict real-world performance reliably.
Multiple complementary strategies. Targeted data enrichment from clinical partners — even 10–20 additional cases per partner makes a meaningful difference. Transfer learning from a foundation model trained on a related task. Synthetic augmentation to oversample the rare class (SMOTE for tabular, GANs or diffusion models for imaging). Class-weighted training to focus learning on the minority class. And realistic intended use constraints — if 50 cases can only support a "decision support flag for clinician review" intended use rather than "autonomous diagnosis," scope the product accordingly.
For a regulatory-grade dataset suitable for a Class IIa submission, expect €500K–€2M+ across 12–18 months. Costs include ethics/IRB approval (€20–50K), clinical site contracting (€20–80K per site), data collection infrastructure (€100–300K), data engineering and quality control (€100–200K), and expert labelling (£50–200 per case, with 5,000–20,000 cases typical). Existing institutional partnerships and federated learning can substantially reduce this.
Yes, but with significant constraints. EMR vendors (Epic, Oracle Health/Cerner) and health data platforms (TriNetX, Komodo Health, IQVIA) license de-identified clinical data for research and product development. Costs run €100K–€1M+ depending on scope. The constraints: re-identification risk requires strict handling protocols, de-identification standards may not match your specific use case, and licensing terms typically restrict commercial deployment without renegotiation. Useful for development; less so for primary validation data.
It substantially reduces GDPR risk but doesn't eliminate it. Federated learning means patient data doesn't leave each institution, which addresses the core data transfer concern. But the model gradients exchanged during training can in some cases be reverse-engineered to reveal training data, and the resulting model is still trained on personal data subject to Article 9 special-category provisions. Differential privacy applied to gradients further reduces this risk. Document the federated architecture in your DPIA and verify with your DPO before assuming GDPR compliance.
SMOTE (Synthetic Minority Oversampling Technique) generates synthetic examples by interpolating between existing examples in feature space — simpler, well-established, works well for tabular data with continuous features. GAN-based synthetic data uses generative adversarial networks to learn the data distribution and generate novel samples — more powerful, especially for high-dimensional data like images, but requires more training data to build a good generator and can suffer from mode collapse. For tabular clinical data with class imbalance, SMOTE is typically sufficient and easier to defend regulatorily. For medical imaging, GANs or diffusion models are required for credible augmentation.