



Проблемът с данните в изкуствения интелект в здравеопазването: как да се обучи клиничен модел, когато няма достатъчно пациенти


Изкуственият интелект в здравеопазването е свързан с парадокс на данните. Тази област генерира повече данни от почти всяка друга. Всяко клинично взаимодействие, всяко сканиране, всеки лабораторен резултат, всеки жизненоважен показател произвежда структурирани и неструктурирани данни в голям мащаб. И въпреки това данните, необходими за обучение на специфичен клиничен модел на изкуствен интелект за конкретна индикация при конкретна популация от пациенти, почти винаги са оскъдни.
Причините са структурни. Ограниченията за поверителност на пациентите правят централизирането на данните правно трудно. Редките състояния означават малък обем пациенти по дефиниция. Историческите данни често са във формати, неподходящи за обучение по машинно обучение, сканирани хартиени записи, свободен текст, непоследователно кодиране. А данните, които съществуват, често са небалансирани: много отрицателни примери (няма заболяване), малко положителни примери (потвърдено заболяване), като положителните примери са точно това, от което моделът трябва да се поучи.
Основателите, които изграждат здравен изкуствен интелект, се сблъскват с този проблем в почти всеки проект. Тази статия разглежда практическите стратегии, които действително работят, не теоретичните, а тези, които сме използвали за изграждане на модели с клинично качество, когато очевидните данни за обучение не са съществували.
Защо „получаването на повече данни“ не е стратегия
Рефлекторният отговор на недостига на данни – събирането на повече данни – често не е наличен във времевите рамки, които са важни за един стартъп.
Проспективно проучване за събиране на данни изисква одобрение от ERB или етичен комитет (6–12 месеца), създаване и сключване на договори за клинично място (3–6 месеца на място), набиране на пациенти и събиране на данни (месеци до години в зависимост от честотата), почистване и етикетиране на данните (седмици до месеци) и задържане на валидационния набор от данни, преди да са налични каквито и да е данни за обучение за вашия модел. За рядко състояние с честота 1 на 10 000, проспективно проучване за събиране на 500 случая може да отнеме десетилетие.
Това не означава, че събирането на проспективни данни е грешно. То е златният стандарт и за продукт в търговски мащаб в крайна сметка е необходимо. Това означава, че за прототипа, пилотния проект и първоначалното подаване на маркировката CE или заявлението за одобрение от FDA са ви необходими стратегии, които работят с данните, които имате или до които можете да получите достъп, в период от 12 до 24 месеца.
Шест стратегии, които работят
Шест практически стратегии обхващат пространството на недостиг на данни за клиничния изкуствен интелект. Повечето успешни програми използват множество стратегии в комбинация, например трансферно обучение плюс слаб надзор плюс синтетично допълване, вместо да разчитат на която и да е една техника.
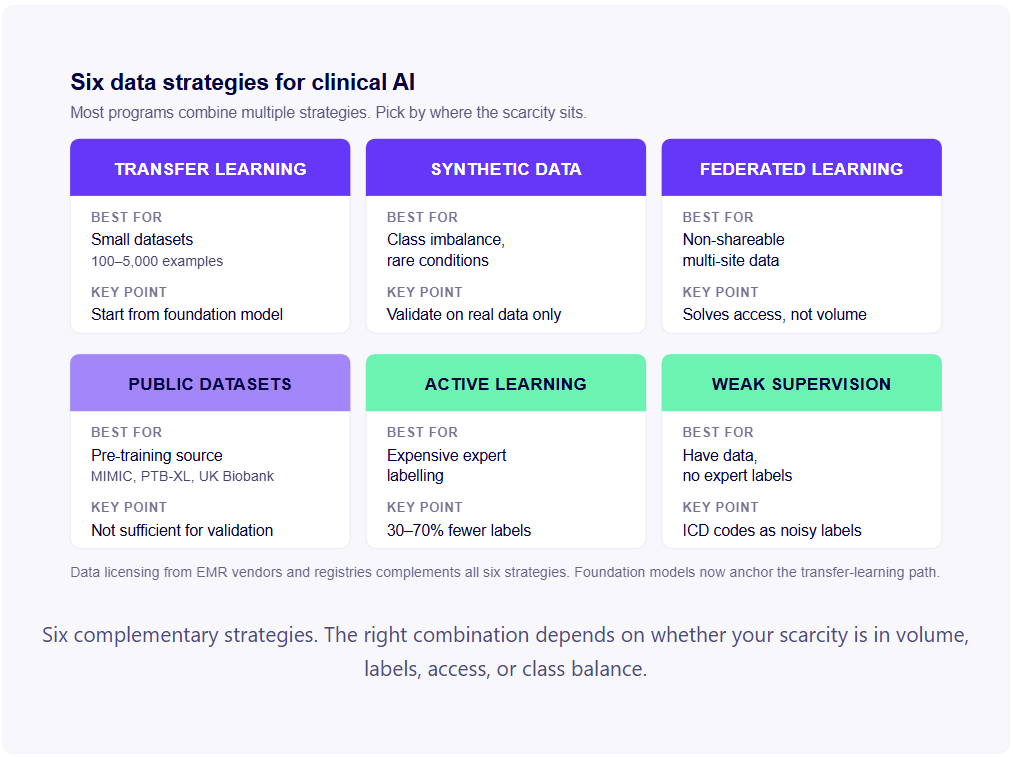
Модели за трансферно обучение и медицински основи
Трансферното обучение е техника за инициализиране на модел с тегла, предварително обучени върху голям, свързан набор от данни, преди фина настройка върху по-малък, специфичен набор от данни. Доскоро това обикновено означаваше да се започне от модел, предварително обучен на ImageNet (за зрение) или езиков модел с общо предназначение като BERT (за NLP), с последваща фина настройка за специфични медицински задачи.
Това се промени значително през последните две години. Доминиращият модел през 2025–2026 г. е да се започне от модел на медицинска основа, обучен специално върху биомедицински или клинични данни:
- Медицинска образна диагностика: MedSAM (сегментация на медицински изображения), BioMedCLIP (биомедицинско изображение-текст), RadFM (модел за основа на радиологията) и все по-специфични за дадена област модели за патология, дерматология и офталмология.
- Клинични сигнали: Предварително обучени ЕКГ трансформатори (ECG-FM, HeartBEiT) и модели на физиологична сигнална основа, обикновено обучени върху десетки милиони немаркирани сигнали от публични и консорциални набори от данни.
- Клиничен текст и структурирани данни: BioBERT, PubMedBERT, ClinicalBERT и биомедицински настроени големи езикови модели като MedGemma, BioMistral и семейството Med-PaLM.
Практическият ефект: докато клиничен модел изискваше над 10 000 етикетирани примера, обучени от нулата, фината настройка на медицински основен модел може да доведе до сравнима производителност с 1000–5000 примера, а в някои нововъзникващи сценарии с нулев и малко опити, дори по-малко. Основният модел вече е научил общата структура на областта; вашата фина настройка го специализира.
За работата по сърдечна диагностика на KARDI AI, предварително обучени модели за ЕКГ представяне, инициализирани върху големи публични ЕКГ набори от данни, осигуриха отправна точка за фина настройка на специфичните сърдечни състояния, представляващи интерес. Предварително обучените представяния улавяха общата ЕКГ морфология; фината настройка ги специализираше за целевия клиничен въпрос.
Регулаторното значение: вашият източник за предварително обучение е важен и трябва да бъде документиран в регулаторното досие. Базовите модели, обучени върху данни с неясен произход, пристрастен състав или непроверимо качество, създават регулаторно излагане, което е трудно да се смекчи по-късно. Изберете базови модели с документирани данни за обучение и публикувана оценка и разкрийте избора си изрично в техническото си досие.
Синтетично увеличаване на данни
Генерирането на синтетични данни използва генеративни модели за създаване на изкуствени примери за обучение, които имитират реални клинични данни. Целта е да се допълни малък реален набор от данни със синтетични примери, като по този начин се увеличи ефективно размерът на набора за обучение, без да се събират допълнителни данни за пациентите.
За медицинска образна диагностика: Генеративни състезателни мрежи (GAN) и дифузионни модели са използвани за генериране на синтетични КТ сканирания, ЯМР изображения и хистопатологични препарати. Ключовото изискване е синтетичните изображения да бъдат едновременно реалистични (неразличими от реалните изображения на модела) и разнообразни (не просто копия на тренировъчните изображения с незначителни смущения).
Регулаторното съображение е важно: ако в обучението се използват синтетични данни, те трябва да бъдат оповестени във вашето регулаторно заявление, а нотифицираният орган или FDA ще очакват доказателства, че синтетичните данни са реалистични и че обучението върху синтетични данни не въвежда систематични отклонения или артефакти в производителността. Наборът от данни за валидиране трябва да бъде изцяло реален. Използването на синтетични данни за валидиране не е приемливо.
За структурирани клинични данни: Вариационните автоенкодери (VAE) и методите на Гаусова копула могат да генерират синтетични записи на пациенти, които запазват статистическата структура на реалните данни (корелации между променливи, гранични разпределения), без да включват действителни записи на пациенти. Това е особено полезно за споделяне на данни, запазващо поверителността — споделяне на синтетични набори от данни за пациенти, които не носят риск за поверителността на отделния пациент, докато се обучават модели, които се обобщават за реалната популация.
За таблични данни с дисбаланс на класовете: SMOTE (Synthetic Minority Oversampling Technique) и неговите варианти генерират синтетични примери за малцинствения клас, обикновено положителни случаи на заболяване, чрез интерполация между съществуващи примери за малцинствени класове в пространството на характеристиките. По-малко мощен от пълните генеративни модели, но изчислително по-прост и добре установен в регулаторната литература.
Ограничението на всички синтетични подходи: моделът се научава да обобщава за реалното разпределение на данните само ако синтетичните данни точно представят това разпределение. Ако вашият генеративен модел има колапс на модата (произвежда само подмножество от разнообразието на реалните данни) или въвежда систематични артефакти, вашият модел се обучава върху пристрастен синтетичен набор от данни и производителността върху реални данни ще бъде по-лоша, отколкото предполага синтетичната валидация.
Федерирано обучение
Федеративното обучение разпределя обучението на модели между множество източници на данни, без да централизира данните. Всеки обект се обучава локално; споделят се само актуализации на моделите (не данни за пациентите). Практическият резултат е модел, обучен върху комбинираните данни от множество обекти, с гаранциите за поверителност, произтичащи от това, че данните никога не напускат всяка институция.
За недостига на данни за здравеопазването с изкуствен интелект, федеративното обучение е най-ценно в два сценария:
Малък обем пациенти на обект, но множество обекти. За редки заболявания или необичайни прояви, всяка отделна болница може да има 50–100 случая в своите досиета. Федерираното обучение в 10 болници ви дава достъп до 500–1000 случая – потенциално достатъчно за смислен модел – без правната и логистична тежест от централизиране на данните.
Данни, които са законово или практически неподлежащи на споделяне. Когато споразуменията за споделяне на данни не са налични, регулаторните рамки забраняват централизацията или институционалното управление предотвратява експорта на данни, федеративното обучение може да е единственият път към обучение на множество обекти.
Федерираното обучение решава проблем с достъпа до данни, а не проблем с обема на данните. Ако агрегираният набор от данни във всички федеративни сайтове е твърде малък за задачата, федералното обучение не променя това.
Ограниченията са реални — разпределение на данни, различни от IID, между сайтовете, комуникационни разходи и влошаване на производителността от градиентен шум — и те трябва да бъдат разгледани във федеративната архитектура и характеризирани в регулаторното предложение.
Външни набори от данни и споделяне на данни преди конкуренцията
Налични са няколко големи публични медицински набора от данни за обучение на модели с изкуствен интелект в здравеопазването, а споделянето на данни преди конкуренцията – където множество конкурентни компании споделят достъп до данни за обучение – е узряло значително през последните пет години.
Полезни публични медицински набори от данни:
- MIMIC-IV: Над 300 000 приема в интензивно отделение в медицински център „Бет Израел Дийконес“; структурирани данни от електронните здравни записи (ЕЗД) и клинични бележки. Изисква споразумение за използване на данни с акредитация и е широко използвано за клинични модели за прогнозиране.
- PhysioNet: Голяма колекция от набори от физиологични сигнали, включително ЕКГ набори от данни (PTB-XL с 21 837 ЕКГ записа), ЕЕГ данни и клинични времеви серии.
- Атлас на раковия геном (TCGA): Геномни и клинични данни за 33 вида рак; широко използван за онкологичен изкуствен интелект.
- Биобанка в Обединеното кралство: кохорта от 500 000 участници с генетични, образни и здравни данни; достъп чрез одобрено заявление за изследване.
- Набор от данни за рентгенография на гръдния кош на NIH: 112 000 рентгенови изображения на гръдния кош с обозначени заболявания; широко използван за торакална образна диагностика с изкуствен интелект.
- Набори от данни за ретинални изображения: Набор от данни за диабетна ретинопатия на Kaggle, IDRiD, Messidor-2.
- Консорциуми за геномни и биобанкови дейности: All of Us (САЩ), FinnGen (Финландия), Estonian Biobank, deCODE (Исландия) — променливи условия за достъп, но значителен мащаб.
Практическото използване на публичните набори от данни: те са най-ценни като източници за предварително обучение или трансфер на знания — използване на публичен набор от данни за инициализиране на модел, който след това се настройва фино върху вашите собствени клинични данни. Използването на публичен набор от данни като основен набор от данни за валидиране обикновено не е приемливо за регулаторни подавания, тъй като популацията от пациенти и условията на придобиване не съответстват на предвиденото ви използване.
Предконкурентното споделяне на данни в науките за живота се осъществява чрез инициативи като Европейското пространство за здравни данни (EHDS), консорциума OHDSI/OMOP (стандартизирани данни от наблюдения от над 130 партньори за данни), различни национални партньорства за здравни данни и консорциуми, специфични за заболяванията. За стартиращи компании, насочени към специфични клинични области, ранното ангажиране с тези инициативи – дори като сътрудник, а не като водещ – осигурява достъп до данни за обучение, които иначе биха изисквали години на събиране на данни за бъдещето.
Активно учене
Ако вашето пречка не са данните, а етикетираните данни — имате клинични записи, но анотирането им изисква скъпоструващо време на клинични експерти — активното обучение намалява разходите за етикетиране, като избира кои случаи да бъдат етикетирани.
Подходът на активното обучение: обучете начален модел върху малък етикетиран набор от начални данни. Използвайте модела за предсказване на базата на немаркирания пул. Идентифицирайте случаите, за които моделът е най-несигурен (обикновено измерени чрез ентропия на прогнозирането или граница между вероятностите от двата най-високи класа). Приоритизирайте тези случаи за експертно етикетиране. Преобучете. Повторете.
Принципът: моделът се учи най-много от случаите, за които е най-несигурен. Случаен подбор на случаи за етикетиране на отпадъците като бюджет за анотиране в случаи, при които прогнозата на модела би била правилна независимо от всичко. Активното обучение концентрира усилията за анотиране там, където то води до най-голямо подобрение в производителността.
Публикувани изследвания показват, че активното обучение може да постигне еквивалентна производителност на модела на пасивното случайно вземане на проби с 30–70% по-малко етикетирани примери, в зависимост от задачата и първоначалния набор от данни. В клиничния изкуствен интелект, където експертните анотации могат да струват 50–200 паунда на случай (време на рентгенолог или специалист), 50% намаление на изискванията за етикетиране е значително – за набор от 5000 случая това са спестени 125 000–500 000 паунда.
Ограничението: активното обучение работи в рамките на разпределението на немаркирания пул. Ако вашият немаркиран пул не включва редки, но важни клинични прояви, активното обучение няма да ви помогне да придобиете етикети за тях — то избира от наличните.
Слаб надзор и програмно етикетиране
Традиционното контролирано обучение изисква примери, етикетирани от експерти. За клиничния изкуствен интелект, експертното етикетиране е скъпо и бавно. Слабото наблюдение използва по-евтини и по-малко точни източници на етикети – клинични кодове, текст на отчети, структурирани шаблони, евристики, базирани на правила – за генериране на шумни етикети, които могат да се използват за обучение на начален модел.
Класическото приложение: използване на ICD диагностични кодове от електронните здравни досиета (ЕЗД) като етикети за обучение. Ако ЕЗД на пациент съдържа ICD код за предсърдно мъждене, това е (шумен) положителен етикет за модел, предсказващ предсърдно мъждене от ЕКГ или физиологични данни. Кодовете са несъвършени – грешки в кодирането, забавяне на кодирането, пропуснати диагнози – но при достатъчно голям набор от данни сигналът надделява над шума.
Рамката Snorkel и подобни инструменти за програмно етикетиране позволяват комбинирането на множество източници на слаби етикети — диагностични кодове, клинични текстови модели, структурирани шаблони, правила за домейни — в вероятностен модел на етикети. Изходните данни от модела на етикетите след това се използват за обучение на модел за машинно обучение надолу по веригата. Този подход е използван за обучение на модели за клинично прогнозиране в голям мащаб в Станфорд, Google Health и големи академични медицински центрове.
За регулаторни документи: моделите, обучени върху слабо контролирани етикети, изискват особено внимателна валидация върху експертно етикетирани множества с ограничение, с прозрачно разкриване на методологията на етикетиране и анализ на ефектите от шума на етикетите върху производителността на модела.
Лицензирането на данни като допълнителен път
Път, който не получава достатъчно внимание в техническата литература, но е все по-често срещан в търговската практика: лицензиране на клинични данни от доставчици на EMR, платформи за здравни данни и регистри .
Основните търговски източници:
- Доставчици на EMR: Epic (изследователска мрежа Cosmos), Oracle Health (преди Cerner), Allscripts. Агрегирани анонимизирани записи от хиляди сайтове, обикновено лицензирани за изследвания и разработване на продукти.
- Платформи за здравни данни: TriNetX, Komodo Health, IQVIA, Truveta. Мрежов достъп до надлъжни клинични данни от партньори в здравните системи.
- Регистри, специфични за заболяванията: Често водени от академични среди, с различни условия за достъп. Силни за редки състояния, където търговските източници са слаби.
Цената варира от 100 000 до 1+ милион евро на лиценз, в зависимост от обхвата (специфично състояние спрямо по-широка мрежа), ексклузивността и предназначението. Ограниченията са реални: рискът от повторна идентификация изисква стриктни протоколи за обработка, стандартите за деидентификация може да не съответстват на вашия специфичен клиничен случай на употреба, а търговското внедряване обикновено изисква предоговаряне на лиценза. Най-полезно за разработка и предварително обучение; по-малко надеждно за първични данни за валидиране, които обикновено трябва да идват от вашите собствени клинични партньорства.
Слой на Закона на ЕС за изкуствения интелект за данни за обучение
За програми, обвързани с ЕС, Законът за изкуствения интелект (ИИ) добавя специфични изисквания за управление на данните за обучение в допълнение към очакванията на MDR за клинична оценка. От август 2026 г., с влезлите в сила разпоредби за ИИ с висок риск, тези изисквания са в сила.
Съответните задължения за данните за обучение:
- Качество и релевантност на данните: документирани доказателства, че данните от обучението, валидирането и тестването са релевантни, представителни и без очевидни грешки за предвидената употреба.
- Статистически свойства: анализ на статистическите свойства на данните за обучение, включително тестване за пристрастия в съответните подгрупи (възраст, пол, етническа принадлежност, съпътстващи заболявания).
- Практики за управление на данни: документирани процеси за събиране и подготовка на данни, включително методология за етикетиране, и направените избори относно предварителната обработка.
- Защита на поверителността и правата: съответствие с GDPR за минимизиране на данните, съгласие и специални категории защити.
Практическото значение: документацията за данни, която е била приемлива само за MDR, може да се нуждае от разширяване за съответствие със Закона за изкуствения интелект (AI Act). Изборът на основен модел, използването на синтетично допълване, архитектурата на федеративното обучение, условията за лицензиране на данни и методологията за етикетиране трябва да бъдат документирани на по-висок стандарт, отколкото е било типично преди. Програмите, които вече са преминали през оценка на съответствието с MDR, имат значително предимство; новите участници трябва да планират документацията за данни за обучение по Закона за изкуствения интелект от първата седмица.
Изграждане на стратегия за данни, преди да изградите модел
Практическото значение на всичко гореизложено: вашата стратегия за данни трябва да бъде проектирана преди архитектурата на вашия модел . Моделът, който можете да изградите, зависи от данните, до които имате достъп и които можете да обозначите. Първото проектиране на модела и след това откриването, че данните не съществуват, води до ситуацията „дванадесет месеца без нищо за обучение“, която прекратява проектите.
Стратегията за данни за стартъп в областта на изкуствения интелект в здравеопазването трябва да обхваща:
- Какви данни за обучение са достъпни сега (публични набори от данни, модели на фондации, институционални партньори, съществуващи записи, лицензирани източници)?
- Какви данни могат да бъдат придобити за 6–12 месеца (федеративни партньори, одобрено от етична комисия проспективно събиране, търговско лицензиране)?
- Какви стратегии за допълване са подходящи за вашия тип данни и регулаторен път?
- Какъв е минималният размер на набора от данни, необходим за нивото на производителност, което изисква предвидената от вас употреба?
- Как ще се запази напълно независимият набор от данни за валидиране от всички данни за обучение, включително допълнени, синтетични и данни преди обучение?
- Как ще бъде документирана стратегията за данни както за клиничната оценка на MDR, така и за съответствието със Закона за изкуствения интелект?
Това е разговорът, който трябва да се проведе преди началото на инженерния проект. Той определя сроковете, разходите и дали планираното от вас подаване на документи до регулаторните органи е постижимо в рамките на текущата ви пътна карта.
Често задавани въпроси
There's no universal number. It depends on task complexity, signal-to-noise ratio, and the performance level your intended use requires. Rough rules of thumb: for binary classification with transfer learning from a relevant medical foundation model, 1,000–5,000 labelled examples can produce a credible Class IIa system. Without transfer learning, 10,000+ examples are typically needed. For rare conditions, targeted enrichment to reach 50–100 confirmed positive cases per condition is the typical lower bound for credible performance estimates.
Yes, and this is standard practice in 2025–2026. Medical foundation models — MedSAM, BioMedCLIP, RadFM, MedGemma, biomedical language models like BioBERT and PubMedBERT — provide pre-trained representations that dramatically reduce the data needed for fine-tuning. Foundation models also drive emerging zero-shot and few-shot performance for clinical tasks. Regulatory documentation needs to disclose the pre-training source and explain how the foundation model was used.
For training, yes, when properly disclosed and characterised. Notified bodies and FDA increasingly accept synthetic data as a training augmentation, provided you document the generation methodology, validate that synthetic samples preserve clinically relevant features, and demonstrate that the model generalises to real data. For validation, no, your validation dataset must be entirely real clinical data. Synthetic validation results don't predict real-world performance reliably.
Multiple complementary strategies. Targeted data enrichment from clinical partners — even 10–20 additional cases per partner makes a meaningful difference. Transfer learning from a foundation model trained on a related task. Synthetic augmentation to oversample the rare class (SMOTE for tabular, GANs or diffusion models for imaging). Class-weighted training to focus learning on the minority class. And realistic intended use constraints — if 50 cases can only support a "decision support flag for clinician review" intended use rather than "autonomous diagnosis," scope the product accordingly.
For a regulatory-grade dataset suitable for a Class IIa submission, expect €500K–€2M+ across 12–18 months. Costs include ethics/IRB approval (€20–50K), clinical site contracting (€20–80K per site), data collection infrastructure (€100–300K), data engineering and quality control (€100–200K), and expert labelling (£50–200 per case, with 5,000–20,000 cases typical). Existing institutional partnerships and federated learning can substantially reduce this.
Yes, but with significant constraints. EMR vendors (Epic, Oracle Health/Cerner) and health data platforms (TriNetX, Komodo Health, IQVIA) license de-identified clinical data for research and product development. Costs run €100K–€1M+ depending on scope. The constraints: re-identification risk requires strict handling protocols, de-identification standards may not match your specific use case, and licensing terms typically restrict commercial deployment without renegotiation. Useful for development; less so for primary validation data.
It substantially reduces GDPR risk but doesn't eliminate it. Federated learning means patient data doesn't leave each institution, which addresses the core data transfer concern. But the model gradients exchanged during training can in some cases be reverse-engineered to reveal training data, and the resulting model is still trained on personal data subject to Article 9 special-category provisions. Differential privacy applied to gradients further reduces this risk. Document the federated architecture in your DPIA and verify with your DPO before assuming GDPR compliance.
SMOTE (Synthetic Minority Oversampling Technique) generates synthetic examples by interpolating between existing examples in feature space — simpler, well-established, works well for tabular data with continuous features. GAN-based synthetic data uses generative adversarial networks to learn the data distribution and generate novel samples — more powerful, especially for high-dimensional data like images, but requires more training data to build a good generator and can suffer from mode collapse. For tabular clinical data with class imbalance, SMOTE is typically sufficient and easier to defend regulatorily. For medical imaging, GANs or diffusion models are required for credible augmentation.